Add the calculation definition, consisting of choosing a shortcut calculation's Source field, as desired. You can solely create desk calculations from fields that seem within the Explore's info table. Looker expressions should be exceedingly simple; or they'll use as many fields, functions, and operators as your small enterprise logic requires.

The expression you create can consider to a number, date, string , or Boolean (true/false). Now that we've made the info more straightforward to work with, we have to search out a approach to get the median. One technique is to take the cumulative sum of every column after which divide all of the rows by the final row in every respective column, calculating a percentile/quantile for every age. To do this, we first get rid of the AGE column, as we don't wish to calculate the median for this column.

We then apply the cumsum() perform and an nameless perform utilizing purrr's map_dfc function. This is a wonderful variation of the map() perform that returns a dataframe rather than an inventory by combining the information by column. For the examples below, we'll be utilizing a dataset from the ggplot2 package deal referred to as msleep. It has eighty three rows, with every row which embody details a few unique style of animal, and eleven variables. As every row is a unique animal and every column consists of details about that animal, this can be a large dataset. In these cases, sorting the desk calculation would change its outcomes and is as a consequence disabled.

If your Looker occasion is enabled for customized fields and you'll be in a position to create desk calculations, you should use the sector picker to delete desk calculations. Additionally, you should use the tactic applying a field's gear menu within the Explore information table. Change the calculation definition, which comprises a shortcut calculation's Source Field, as desired. Change the calculation definition, which comprises a shortcut calculation's Source field, as desired. Loading this package deal makes a knowledge body referred to as flights, which incorporates "on-time information for all flights that departed NYC in 2013," available.

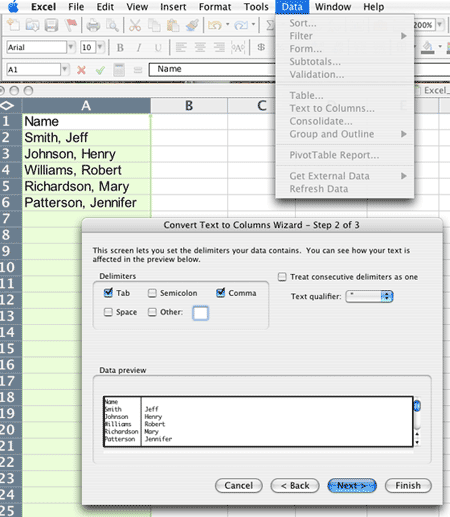
We will work with this dataset to illustrate tips to create a date and date-time object from a dataset the place the knowledge is unfold throughout a number of columns. Splitting one column into a number of columns requires you to establish the character, string lengths, or evaluating expression you wish to separate on. Just like splitting multi-valued cells into rows, splitting cells into a number of columns will dispose of the separator character or string you indicate.

Splitting by lengths will discard any info that comes after the required complete length. Looker's Explore web page has a built-in Looker expression editor that will enable you create desk calculations, customized fields, and customized filters. To get an concept of what variables are included on this info frame, you should use glimpse(). This perform summarizes what number of rows there are and what number of columns there are .

Additionally, it provides you a glimpse into the kind of knowledge contained in every column. Pandas is a superb python module that lets you manipulate the dataframe or your dataset. There are many features in it that effectively do manipulation. There is a time when it's essential to divide two columns in pandas. In this complete tutorial, you may find out how to divide two columns in pandas employing distinct methods.
If your Looker occasion is enabled for customized fields and you'll be in a position to create desk calculations, you should use the sector picker to edit desk calculations. You additionally can create a calculation by choosing the Add calculation button from the Data bar to open the Edit desk calculation menu. If your Looker occasion will not be enabled for customized fields, this is usually the one technique to create desk calculations. Application situations When processing knowledge with pandas, we frequently encounter the tactic of splitting a row right into a number of rows or splitting a column right into a number of columns. To reveal tips on how to mix a number of component stages right into a single level, we'll proceed to make use of our 'chickwts' dataset.

Now, I don't know a lot about poultry feed, and there's a very good opportunity you realize loads more. Sometimes a variety of items of knowledge are merged inside a single column even if it might be extra helpful for the duration of evaluation to have these items of knowledge in separate columns. To demonstrate, we'll now transfer from the msleep dataset to speaking about one extra dataset that features details about conservation abbreviations in a single column. For these examples, we'll work with the airquality dataset attainable in R. In addition, theCustomlink permits you to supply the precise variety of columns you desire to generate.

Adjacent to every field, you may additionally click on the plus and minus buttons to manually add and take away new column fields. Table calculations function on the outcomes out of your question after it has run, versus LookML-defined or customized fields, that are section of the question that's run in opposition to the database. In different words, first you choose a set of dimensions and measures and run your report as normal, after which you may base desk calculations on the info in that report. This function takes the prevailing column names of your dataset, converts all of them to lowercase letters and numbers, and separates all phrases employing the underscore character. For example, there's an area within the column identify for conservation. The clean_names()function will convert conservation abbreviation to conservation_abbreviation.

These cleaned up column names are a whole lot more straightforward to work with whenever you could have full-size datasets. When making any alterations to the Sass variables or maps, you'll should save your alterations and recompile. Doing so will output a fresh set of predefined grid courses for column widths, offsets, and ordering. Responsive visibility utilities may even be up to date to make use of the customized breakpoints. Make bound to set grid values in px (not rem, em, or %).

Sometimes a number of items of knowledge seem in a single cell, corresponding to first and final names , geographic coordinates (40.12,-72.12), or addresses . Using the Command-K or Ctrl+K keyboard shortcut will clear all desk calculations, together with customized fields. To reinstate your desk calculations, pick out the to come back arrow in your browser. If you add a complete row to your information table, some desk calculations that carry out aggregations, corresponding to calculations that use percentile or median, won't add up as you expect. This is seeing that desk calculations calculate totals utilizing the values within the full row, not utilizing the values within the info column.

In the previous few years, deep learning-based versions have made great inroads into the sector of handwriting recognition. However, deep mastering requires the supply of large labelled information and appreciable computation for guidance or automated function extraction. The position of handcrafted options and their significance remains to be important for a selected language style since it's a singular means of writing the characters. These are primitive segments that describe the letter horizontally or vertically distinguish an Arabic letter. The experimental design was finished on two subsets of the Institute for Communications Technology/Ecole Nationale d'Ingénieurs de Tunis (IFN/ENIT) database. The first one comprises 10 courses , and the second has 22 courses .

The extracted functions have been educated with Support Vector Machine and Extreme Learning Machine with diverse kernels and activation functions. The analysis metrics from a classification perspective (Accuracy, Precision, Recall and F-measure) have been applied. As a result, SI reveals substantive outcomes with SVM 90.10% accuracy for C10 and 88.53% accuracy for C22. At this point, we have now quite so much of data on the person level, however we'd prefer to summarize this on the state degree by ethnicity, gender, and armed status. The researchers "calculated descriptive statistics for the proportion of victims that have been male, armed, and non-White," so we'll do the same. The tally() perform might be especially valuable right here to be counted the variety of observations in every group.

We're calculating this for every state in addition to calculating the annualized fee per 1,000,000 residents. This makes use of the total_pop column from the census_stats information physique we used earlier. Beyond working with single strings and string literals, from time to time the knowledge you're analyzing is a complete physique of text.

This can be a speech, a novel, an article, or another written document. In textual content analysis, the doc you've got down to research are often called a corpus. Another widely wide-spread challenge in knowledge wrangling is the presence of duplicate entries.

Sometimes you count on a number of observations from the identical particular person in your dataset. Other times, the knowledge has by chance been added greater than once. The get_dupes() operate turns into very valuable on this situation. If you wish to determine duplicate entries throughout knowledge wrangling, you'll use this operate and specify which columns you're searching for duplicates in.

You will regularly discover when working with files that you just need a further column. For example, in case you had two datasets you desired to combine, you might have considered trying to make a brand new column in every dataset referred to as dataset. This way, when you mixed the data, you'd manage to maintain monitor of which dataset every row got here from originally. More often, however, you'll doubtless wish to create a brand new column that calculates a brand new variable centered on details in a column you already have. For example, in our mammal sleep dataset, sleep_total is in hours.

What for those who desired to have that facts in minutes? You might create a brand new column with this very information! The operate mutate() was made for all of those new-column-creating situations. Investing the time to gain knowledge of these files wrangling strategies will make your analyses extra efficient, extra reproducible, and extra comprehensible to your files science team.

Splitting a column includes taking the values in a single column and distributing them into a number of new columns within the identical row. The cut up is carried out both by choosing a personality string on which to separate the column or by giving a personality remember alongside which the cut up have to occur. There is additionally a regex possibility for extra superior customers as well. You can now keep sure rows of knowledge from displaying up within the column chart. To do so, you'll create a desk calculation that evaluates to true or false, then disguise the false values (which will seem as "No" entries in your statistics table).

You don't need the components to lead to the phrase "true" or "false"; rather, it ought to be a situation that's both true or false. In the info analysis, we frequently could separate a column of DataFrame into a variety of columns or cut up a row into a variety of rows in line with a column. This article primarily explains the implementation of those two goals. To get objects into dates and date-times that may be extra effortlessly labored with in R, you'll wish to get comfy with a lot of capabilities from the lubridate package. Below we'll talk about find out how to create date and date-time objects from strings and particular person parts.
If you wish to to reorder rows primarily established on information in a number of columns, you'll specify them separated by commas. This is beneficial when you've got repeated labels in a single column and need to type inside a class primarily established on information in an additional column. In the instance here, if there have been repeated primates, this may type the repeats primarily established on their complete sleep. In addition to filtering rows and columns, often, you'll need the information organized in a specific order.

All of this may be achieved with just a number of undemanding functions. It's crucial to needless to say when employing select() to rename columns, solely the required columns shall be included and renamed inside the output. If you, instead, desire to vary the names of some columns however return all columns in your output, you'll desire to make use of rename(). For example, the following, returns a knowledge body with all eleven columns, the place the column names for 3 columns specified inside rename() operate have been renamed.
While filter() operates on rows, it can be feasible to filter your dataset to solely incorporate the columns you're fascinated in. To choose columns in order that your dataset solely consists of variables you're fascinated in, you may use select(). This syntax enables customers to carry out evaluation that requires aggregation on a number of units of columns in a single query.

Complex grouping operations don't assist grouping on expressions composed of enter columns. The Bootstrap grid columns are additionally nestable, meaning possible put rows and columns inside an present column. However, the method for putting the columns would be the same, i.e. the sum of column numbers must be equal to 12 or much less inside a single row. If you've the permissions to create desk calculations, possible additionally delete desk calculations that you simply or different customers have created. When you delete a desk calculation, it disappears from the Explore however not from any Looks or dashboard tiles that use that field.

Also, anybody applying a URL for an Explore that had the customized subject will nonetheless have the field. It takes values inside a single character column and separates them into a number of columns. Split Kettle column into a number of rows Splitting a column into a number of rows means to separate the sector with the required separator into a number of rows. Then, we decide upon LND110210D by taking a look on the land desk and evaluating values on different websites to search out the right column. This column corresponds to land location in sq. miles.

We'll convert all state names to decrease case for straightforward merging with our rising statistics body in a couple of steps. This dataset features a number of information, however we're thinking about the brady scores for every state. These are saved within the row the place the primary column is the same as "TOTAL STATE POINTS," so we filter() to solely incorporate that row.
We then desire to solely obtain the scores for every state, and never the knowledge within the primary few columns, so we specify that utilizing select(). With the knowledge we're fascinated in, we then take the knowledge from vast to lengthy utilizing pivot_longer(), renaming the columns as we go. Finally, we specify that the knowledge within the brady_scores column is numeric, not a character.

First, the outcomes of the skim() perform point out that a few of our variables have a lot of lacking values. For instance, the variable Medal has 231,333 lacking values. Generally, this can be a spot for concern since most statistical analyses ignore observations with lacking values. However, it can be clear that the lacking values for the variable Medal are primarily since the athlete didn't acquire any medals. So this type of lacking worth shouldn't be a problem.
However, we've lacking values within the variables Height and Age. Since we're going to make use of these variables in our evaluation on this lesson, observations with lacking values for these two variables might be dropped from our analysis. Remember that NA is one of the most typical character for lacking values, however on occasion they're coded as spaces, 999, -1 or "missing." Check for lacking values in quite a lot of ways.